Read time: 7 minutes
Your background workers might look healthy, but are you sure they did not stop working hours ago?
Your monitoring shows them running. CPU usage looks normal. But your queue is growing by thousands of messages per hour because every worker is stuck retrying the same failed database connection.
I covered health checks for .NET APIs here, but background workers need a different approach.
APIs fail fast and obviously. Workers fail slowly and quietly—burning resources on operations that will never succeed.
The fix is surprisingly simple: wire up the built-in health checks middleware with a component that actually monitors your worker’s dependencies in real-time.
Today, I’ll show you how to create a health-aware background worker.
Let’s dive in.
Our worker service
Here’s the worker service we are starting with. It’s responsible for the actual background work, like processing database records or polling a queue, which would happen in StartProcessingAsync:
public class Worker(ILogger<Worker> logger) : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
logger.LogInformation("Simple worker started");
await StartProcessingAsync(stoppingToken);
await Task.Delay(Timeout.Infinite, stoppingToken);
}
private async Task StartProcessingAsync(CancellationToken cancellationToken)
{
logger.LogInformation("START doing work");
// TODO: Add your actual work here
// For example: start processing database records, polling a queue, etc.
await Task.CompletedTask;
}
}
Currently, this worker is completely unaware of the health status of any of its dependencies, which includes a PostgreSQL database and an Azure Service Bus queue, as we can see in Program.cs:
var builder = Host.CreateApplicationBuilder(args);
builder.AddNpgsqlDbContext<HealthyWorkerContext>("todosdb");
builder.AddAzureServiceBusClient("serviceBus");
builder.Services.AddHostedService<Worker>();
var host = builder.Build();
await host.MigrateDbAsync();
host.Run();
If either PostgreSQL or Service Bus starts experiencing any issues (common in the cloud), our worker will begin failing, logging tons of errors and potentially sending hundreds of messages to our dead-letter queue.
To prevent this, let’s start by keeping track of the health of the worker and its dependencies.
Keeping track of the health status
Let’s start by adding a new class that will store our current overall health status and that can also raise a simple event to report it:
public class HealthStatusTracker
{
private volatile bool _isHealthy = false;
public bool IsHealthy => _isHealthy;
public event Action<bool>? HealthStatusChanged;
public void UpdateHealthStatus(bool isHealthy)
{
var previousStatus = _isHealthy;
_isHealthy = isHealthy;
if (previousStatus != isHealthy)
{
HealthStatusChanged?.Invoke(isHealthy);
}
}
}
Now, let’s introduce a new background service that will check the current health status on a periodic basis and report it via our new tracker:
public class HealthMonitorWorker(
HealthCheckService healthCheckService,
HealthStatusTracker healthStatusTracker,
ILogger<HealthMonitorWorker> logger) : BackgroundService
{
private readonly TimeSpan _healthCheckInterval = TimeSpan.FromSeconds(10);
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
logger.LogInformation("Health monitor worker started");
while (!stoppingToken.IsCancellationRequested)
{
var healthReport = await healthCheckService.CheckHealthAsync(stoppingToken);
var isHealthy = healthReport.Status == HealthStatus.Healthy;
healthStatusTracker.UpdateHealthStatus(isHealthy);
logger.LogInformation(
"Health check completed. Status: {Status}",
healthReport.Status);
await Task.Delay(_healthCheckInterval, stoppingToken);
}
logger.LogInformation("Health monitor worker stopped");
}
}
A key insight here is the use of the built-in HealthCheckService, which is part of the Health Checks middleware, and that can report the health status of all of the dependencies that are contributing health info to it.
Now, let’s make sure we register both our HealthStatusTracker and HealthMonitorWorker with the service container, so they start along with our main worker:
var builder = Host.CreateApplicationBuilder(args);
builder.AddNpgsqlDbContext<HealthyWorkerContext>("todosdb");
builder.AddAzureServiceBusClient("serviceBus");
builder.Services.AddSingleton<HealthStatusTracker>();
builder.Services.AddHostedService<HealthMonitorWorker>();
builder.Services.AddHostedService<Worker>();
var host = builder.Build();
await host.MigrateDbAsync();
host.Run();
Finally, we should also register the Health Checks middleware, or none of this will work.
This is pretty easy to do with a call to builder.Services.AddHealthChecks() or, if you are using .NET Aspire, with a call to AddServiceDefaults():
var builder = Host.CreateApplicationBuilder(args);
builder.AddServiceDefaults();
builder.AddNpgsqlDbContext<HealthyWorkerContext>("todosdb");
builder.AddAzureServiceBusClient("serviceBus");
builder.Services.AddSingleton<HealthStatusTracker>();
builder.Services.AddHostedService<HealthMonitorWorker>();
builder.Services.AddHostedService<Worker>();
var host = builder.Build();
await host.MigrateDbAsync();
host.Run();
AddServiceDefaults() comes with Aspire’s ServiceDefaults project and will do a bunch of must-have stuff for you, beyond just health checks. If you are new to .NET Aspire, check my beginner tutorial here.
Now, let’s update our worker so it becomes health-aware.
Using the HealthStatusTracker
All we need to do now is inject our HealthStatusTracker into our Worker and react to its health status notifications:
public class Worker(
HealthStatusTracker healthStatusTracker,
ILogger<Worker> logger) : BackgroundService
{
private bool isProcessing = false;
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
// Subscribe to health status changes
healthStatusTracker.HealthStatusChanged += OnHealthStatusChanged;
logger.LogInformation("Simple worker started");
// Initial check - start processing if healthy
if (healthStatusTracker.IsHealthy)
{
await StartProcessingAsync(stoppingToken);
}
await Task.Delay(Timeout.Infinite, stoppingToken);
}
public override async Task StopAsync(CancellationToken cancellationToken)
{
// Unsubscribe from health status changes
healthStatusTracker.HealthStatusChanged -= OnHealthStatusChanged;
await StopProcessingAsync(cancellationToken);
logger.LogInformation("Simple worker stopped");
await base.StopAsync(cancellationToken);
}
private async void OnHealthStatusChanged(bool isHealthy)
{
if (isHealthy)
{
await StartProcessingAsync(CancellationToken.None);
}
else
{
await StopProcessingAsync(CancellationToken.None);
}
}
private async Task StartProcessingAsync(CancellationToken cancellationToken)
{
if (!isProcessing)
{
isProcessing = true;
logger.LogInformation("START doing work - Application is healthy");
// TODO: Add your actual work here
// For example: start processing database records, polling a queue, etc.
await Task.CompletedTask;
}
}
private async Task StopProcessingAsync(CancellationToken cancellationToken)
{
if (isProcessing)
{
isProcessing = false;
logger.LogWarning("STOP doing work - Application is unhealthy");
// TODO: Add your cleanup here
// For example: stop processing database records, stop polling a queue, etc.
await Task.CompletedTask;
}
}
}
As you can see, any time our HealthStatusTracker reports a change in our application’s (and dependencies) health, we handle the HealthStatusChanged event and start or stop processing work.
How quickly we can react to an unhealthy situation depends on the interval you configure in HealthMonitorWorker, but this should dramatically reduce all those errors and piled up messages.
Now, let’s try it out.
Reacting to health status changes
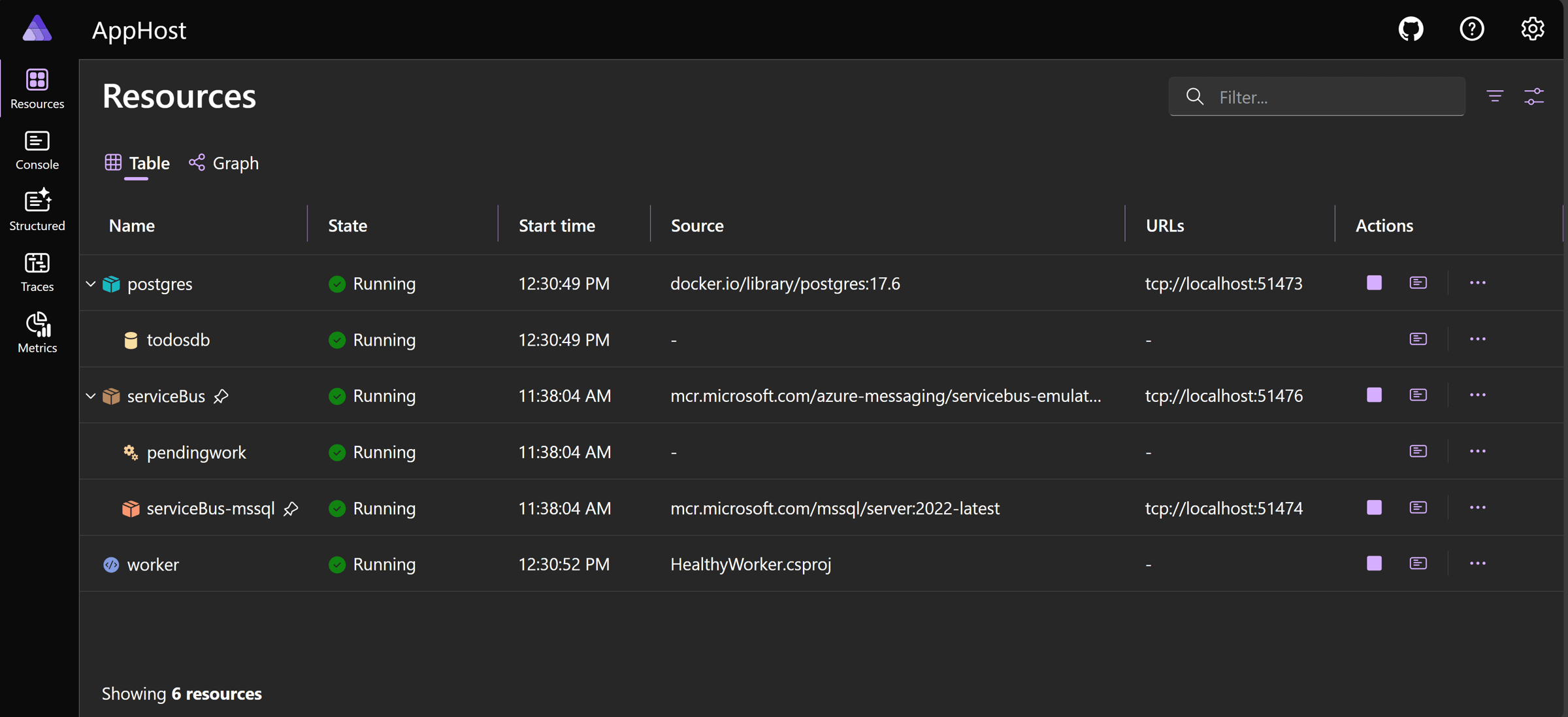
Since I added .NET Aspire to my repo, I can easily start my worker with all dependencies and see the initial status of everything in the Dashboard:
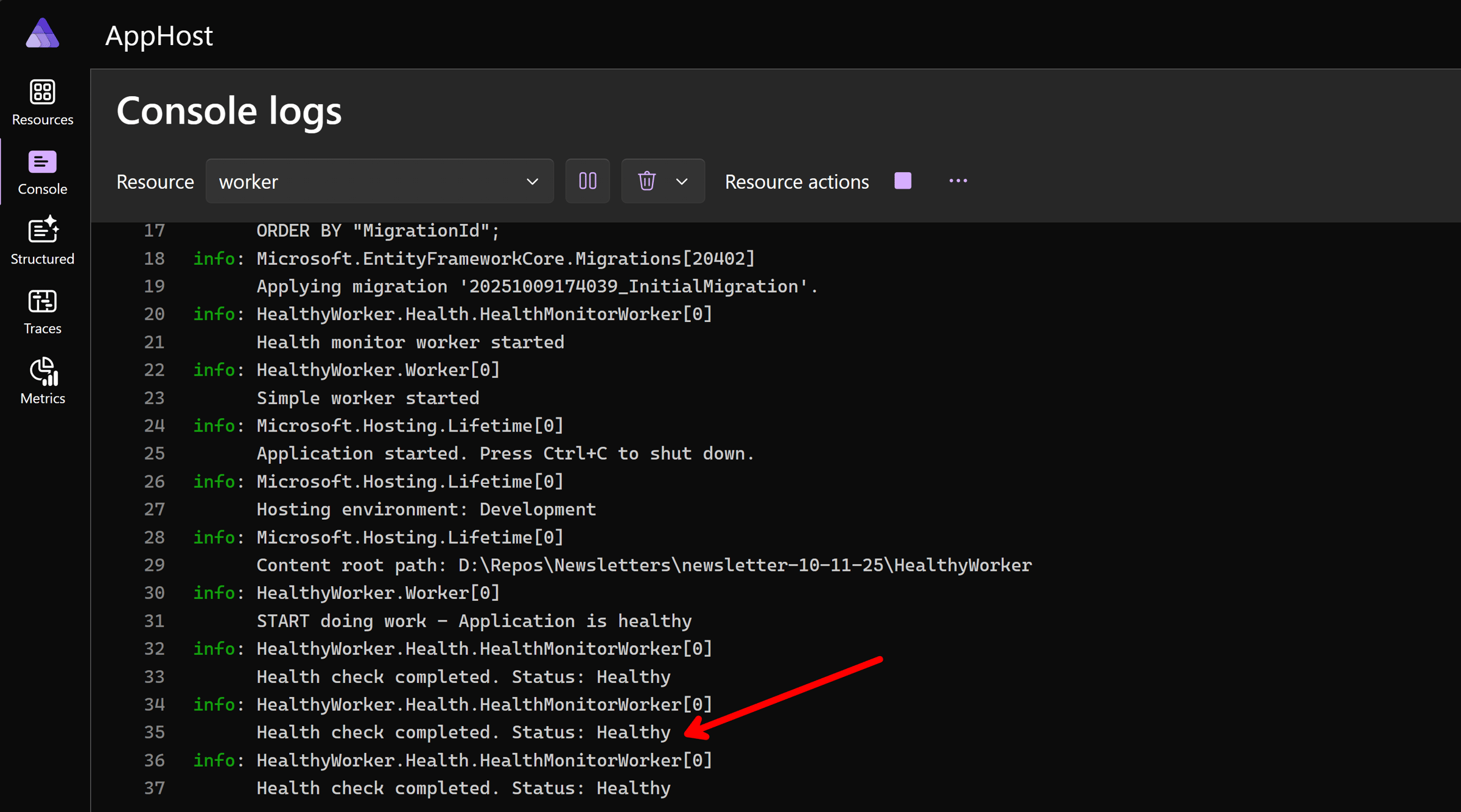
Now, if we dive into the Worker logs, we should see its health status being reported every 10 seconds:
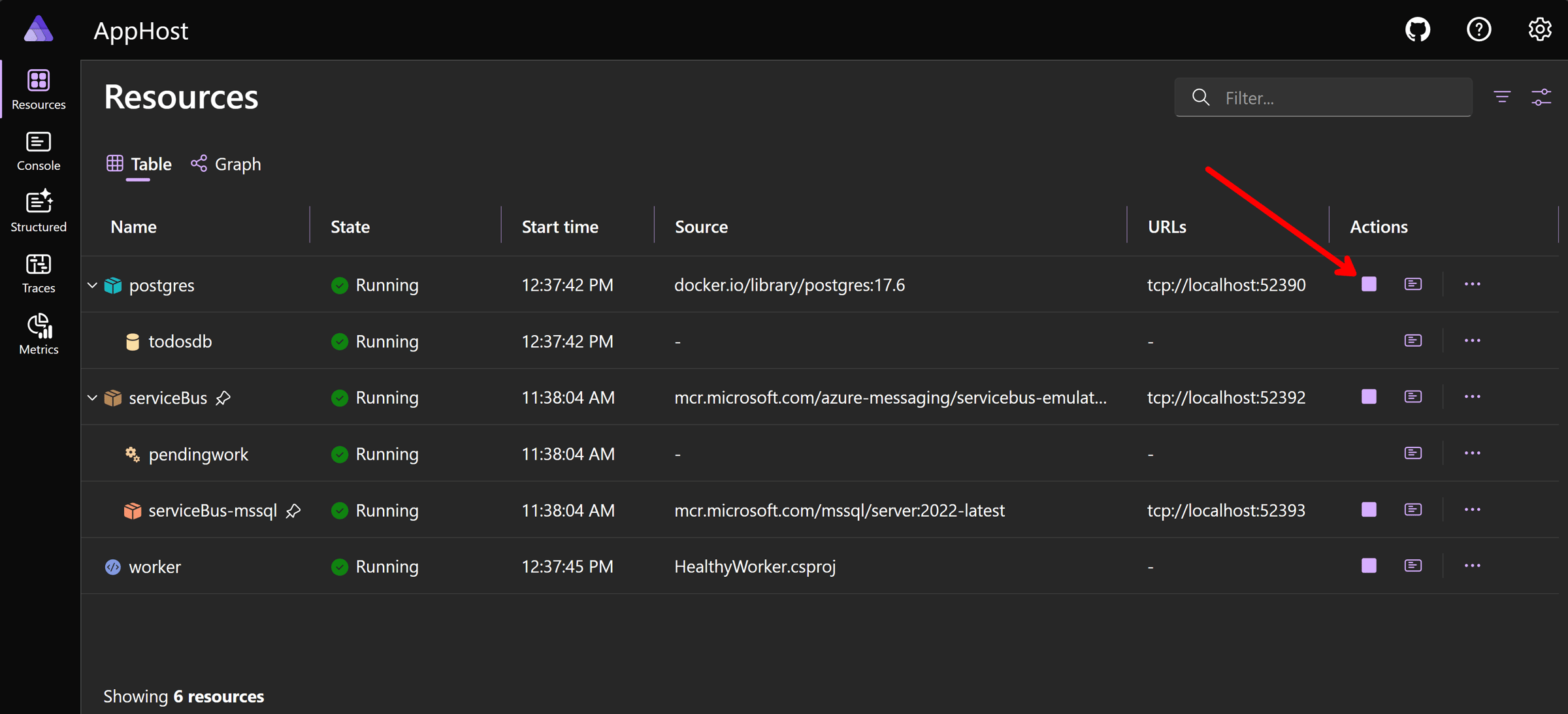
Great. Now, let’s simulate our PostgresSQL server going completely down by stopping it in the Dashboard:
Let’s look at those worker logs again to see if it notices the issue:
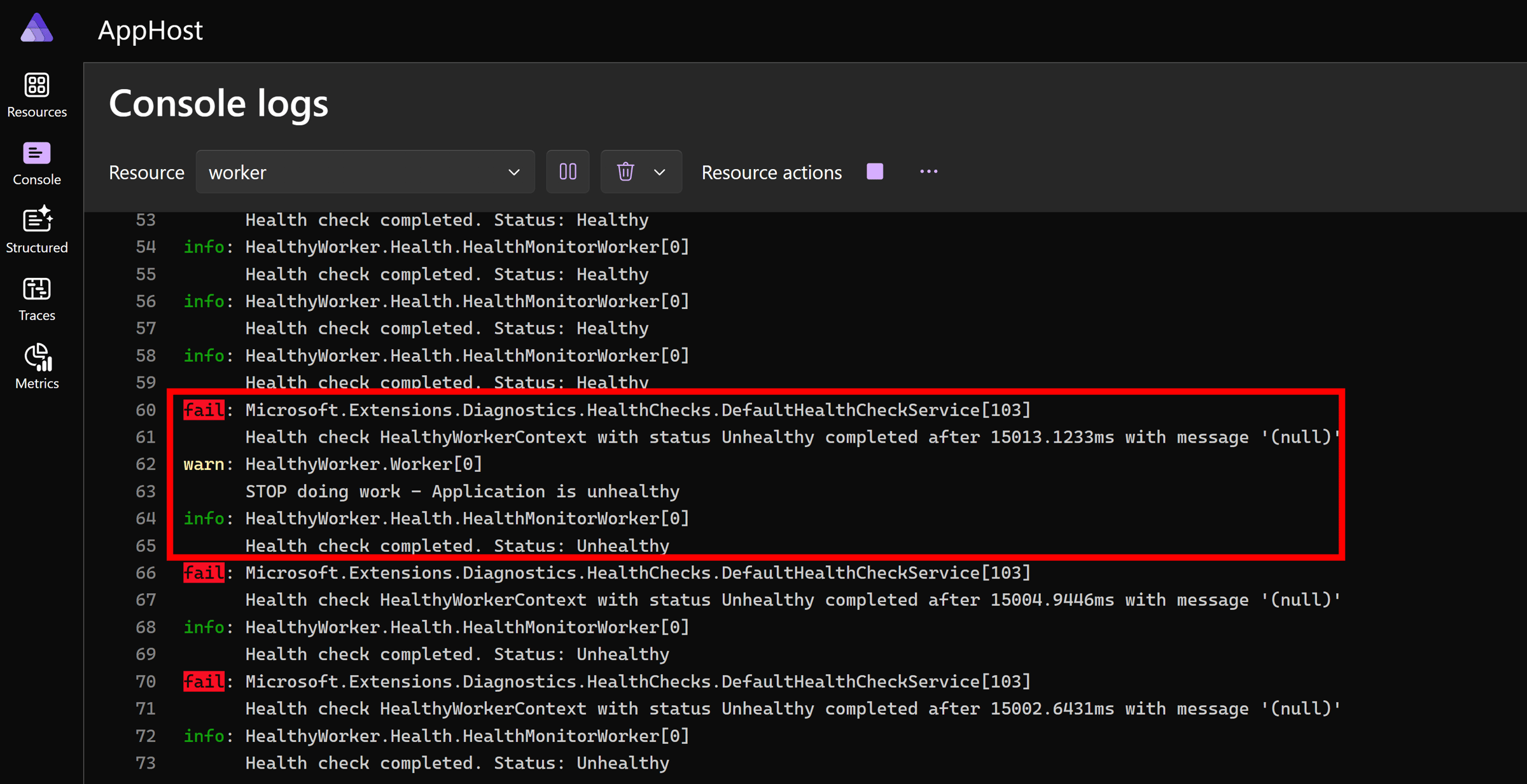
Nice! The worker stopped doing work, although it keeps checking for health changes to know when to restart.
Let’s simulate PostgreSQL coming back by restarting the resource in the Dashboard:
Let’s see those logs again to see if we are back into a healthy state:
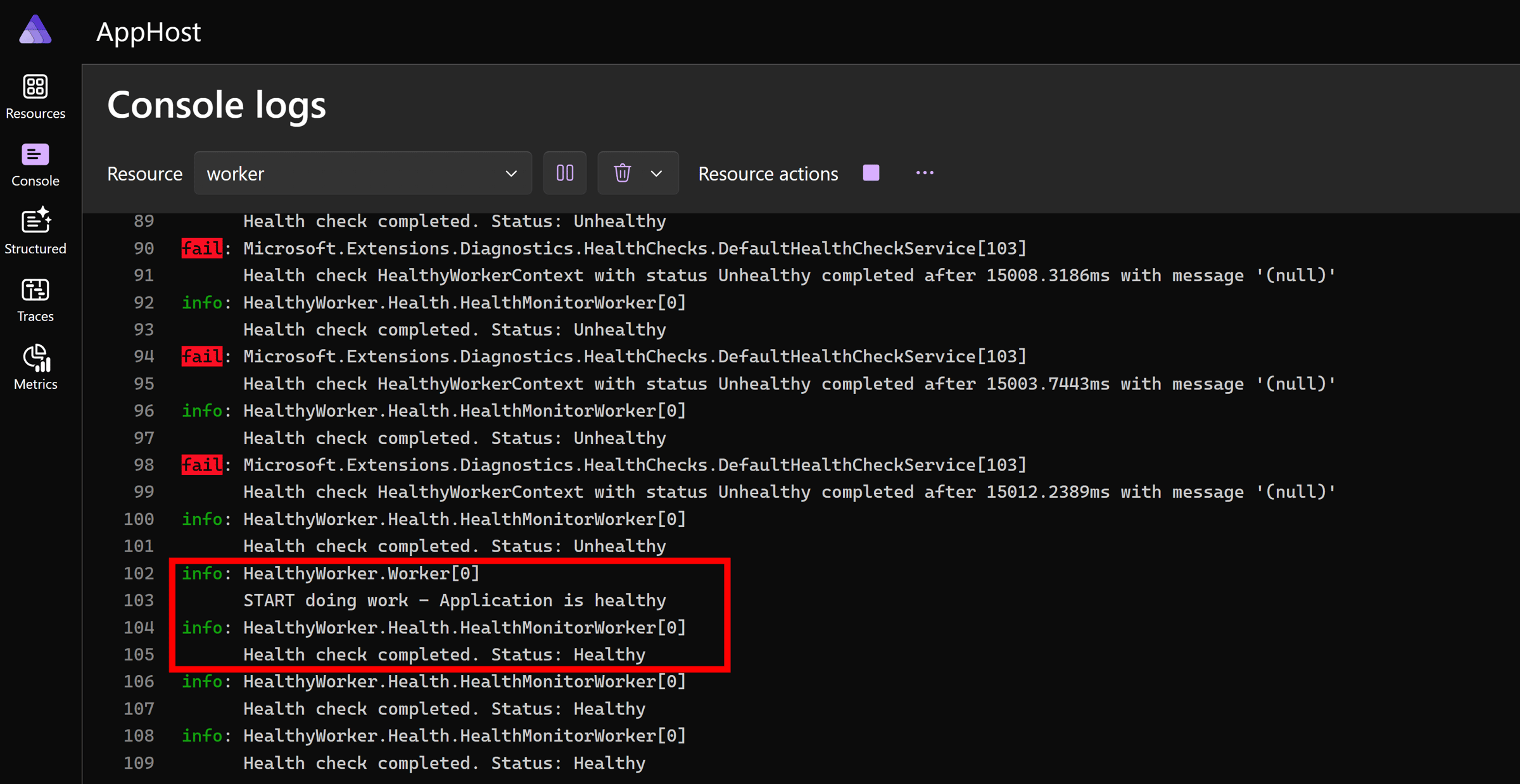
The worker indeed noticed PostgreSQL is back, and therefore resumed normal operation.
Mission accomplished!
Wrapping Up
Background workers are easy to forget, until they fail silently.
By wiring up health checks, a HealthStatusTracker, and a monitoring worker, you’ve made sure your background jobs won’t keep running blind when the system is unhealthy.
This is how you make reliability visible for applications that can self-heal.
Not with dashboards full of red lights, but with code that knows when something’s wrong—and reacts automatically.
And that’s it for today.
See you next Saturday.
P.S. I cover lots more about workers and how to use them to scale your .NET systems in my Payments, Queues & Workers course.
Whenever you’re ready, there are 3 ways I can help you:
-
.NET Backend Developer Bootcamp: A complete path from ASP.NET Core fundamentals to building, containerizing, and deploying production-ready, cloud-native apps on Azure.
-
Building Microservices With .NET: Transform the way you build .NET systems at scale.
-
Get the full source code: Download the working project from this article, grab exclusive course discounts, and join a private .NET community.